
1. 성능 데이터 모델링의 개요
[1] 성능 데이터 모델링의 정의
- 데이터 모델 구조에 의해 성능 저하
- 데이터가 대용량이 됨으로 인해 불가피하게 성능 저하
- 인덱스의 특성을 충분히 고려하지 않고 인덱스를 생성함으로 인해 성능 저하
[2] 성능 데이터 모델링 수행시점
- 사전에 할수록 비용이 들지 않는다. 분석, 설계 단계에서 실행되어야 한다.
[3] 성능 데이터 모델링 고려사항
1) 정규화 수행
2) 데이터베이스 용량산정 수행
3) 데이터베이스에 발생되는 트랜잭션의 유형파악
4) 용량과 트랜잭션의 유형에 따라 반정규화 수행
5) 이력모델 조정, PK/FK 조정, 슈퍼타입/서브타입 조정 등을 수행
6) 성능관점에서 데이터 모델 검증
2. 정규화와 성능
[1] 정규화를 통한 성능 향상 전략
- 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반속성을 의존자로 하여 입력/수정/삭제 이상을 제거한다.
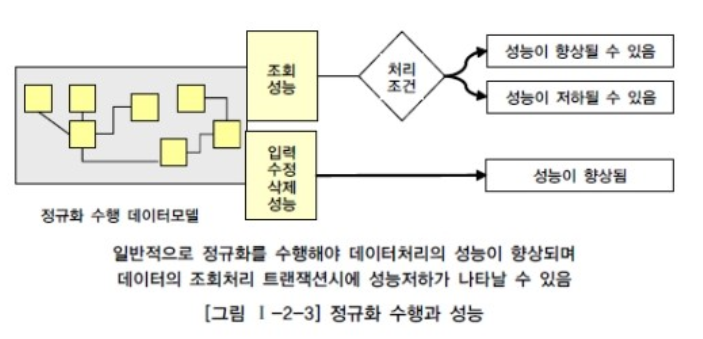
[2] 반정규화된 테이블의 성능 저하
- 정규화를 진행하면 조회성능이 저하된다는 것은 고정관념이다.
3. 반정규화와 성능
[1] 반정규화를 통한 성능향상 전략
- 정의 : 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상, 단순화를 위해 중복, 통합, 분리 등을 수행
-> 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되거나 경로가 너무 멀어, 조인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행

- 적용방법

[2] 반정규화 기법
1) 테이블 반정규화

2) 칼럼 반정규화

3) 관계 반정규화

4. 대량 데이터에 따른 성능
[1] 대량 데이터 발생에 따른 테이블 분할

- 성능저하의 원인
1) 하나의 테이블에 데이터 대량 집중
2) 하나의 테이블에 여러 칼럼 존재
-> 칼럼수가 적은 테이블에서 데이터를 처리하게 되면 디스크의 I/O량이 감소하여 성능이 향상된다.
3) 대량의 데이터가 처리되는 테이블 -> 인덱스를 적절하게 구성하면 이를 줄일 수 있음
4) 대량의 데이터가 하나의 테이블에 존재
5) 칼럼이 많아지는 경우
[2] 대량 데이터 저장 및 처리로 성능저하
1) 파티셔닝(가장 많이 사용)
- 적용대상 : 대상 테이블이 날짜, 숫자 값으로 분리 가능하고, 각 영역별로 트랜젝션이 분리
- 장점 : 데이터 보관주기에 따라 테이블에 데이터를 쉽데 지우는 것이 가능
- 프로그램은 하나의 테이블에 접근하면 내부적으로 RANG으로 구분된 테이블에서 트랜젝션 처리
2) List Partition
- 장점 : 대용량데이터를 특정 값에 따라 분리, 저장 가능
- 단점 : 쉽게 삭제되는 기능이 없음
- 프로그램은 하나의 테이블에 접근하면 내부적으로 LIST로 구분된 파티션테이블에서 트랜젝션 처리
3) Hash Partition
- 저장된 해시 조건에 따라 해시 알고리즘이 적용되어 테이블 분리
- 데이터 확인이 어렵고 삭제 불가
[3] 테이블에 대한 수평/수직 분할의 절차
1) 4가지 원칙
1. 데이터 모델링을 완성한다.
2. 데이터 베이스 용량선정을 한다. -> 칼럼수 고려
3. 대량 데이터가 처리되는 테이블에 대해 트랜젝션 처리 패턴을 분석
4. 칼럼 단위로 집중화된 처리가 발생하는지, 로우 단위로 집중화된 처리가 발생하는지 분석하여 집중화된 단위로 테이블을 분리하는 것을 검토
- 칼럼 수가 많으면? -> 1:1로 분리 가능한지 검토
- 칼럼수는 적으나 데이터량이 많다면? -> 파티셔닝 고려
5. 데이터베이스 구조와 성능
[1] 슈퍼/서브타입 모델의 성능고려 방법
1. 개요
- 최근에 많이 쓰이는 이유 : 업무를 구성하는 데이터를 공통과 차이점의 특징을 고려하여 효과적으로 표현가능
- 슈퍼타입 : 공통부분
- 서브타입 : 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성
- 논리적 데이터 모델에서 이용, 분석 단계에서 많이 쓰임
- 물리적 데이터 모델로 설계 시, 문제점이 나타남 (1:1이나 All in one 타입이 되어버림)
[2] 슈퍼/서브타입 데이터 모델의 변환

- 성능저하의 원인 3가지
1) 트랜젝션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union 연산에 의해 성능이 저하될 수 있다. (ex. 이해관계인/매수인/대리인)
2) 트랜젝션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합되어 있어 불필요하게 많은 양의 데이터가 집약되어 있어 성능이 저하되는 경우. (ex. 도서정보 -> 일반도서 테이블의 전자책 정보)
3) 트랜젝션은 항상 슈퍼+서브 타입을 공통으로 처리하는데 개별로 유지되어 있거나 하나의 테이블로 집약되어 있어 성능이 저하되는 경우 (ex. 이해관계인/매수인/대리인)
- 슈퍼/서브 타입의 변환 기준? : 데이터의 양과 해당 테이블에 발생되는 트랜젝션의 유형
1) 데이터가 소량 : 데이터 처리의 유연성을 고려하여 가급적 1:1 관계를 유지하는 것이 좋음
2) 데이터가 대량 : 3가지의 변화방법
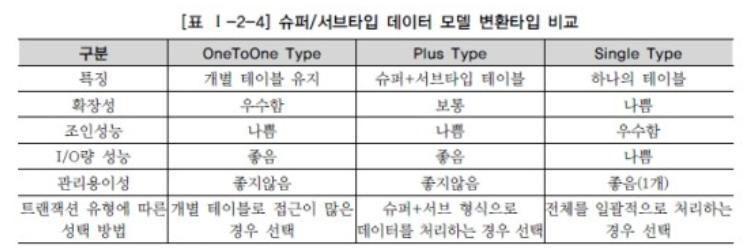
3) 슈퍼/서브 타입의 데이터 모델의 변환 기술
- one to one type : 개별로 발생되는 트랜젝션에 대해서는 개별 테이블로 구성(1:1)
- plus type : 슈퍼+서스타입에 대해 발생하는 트랜젝션에 대해서는 슈퍼+서브타입으로 구성
- single type : 전체를 하나로 묶어 트랜젝션이 발생할 때는 하나의 테이블로 구성
[3] 인덱스 특성을 고려한 PK/FK 데이터베이스 성능향상
1) PK/FK 칼럼순서와 성능개요
- 인덱스의 중요성 : 데이터를 조작할 때 가장 효과적으로 처리될 수 있도록 접근경로를 제공하는 오브젝트
- PK/FK 설계의 중요성 : 데이터에 접근할 때 접근 경로를 제공한다는 측면에서 중요함. 프로젝트 설계 시 설계단계 말에 칼럼의 순서를 조정하는 것이 필요하다.
- PK 순서의 중요성 : 물리적인 데이터 모델링 단계에서는 스스로 생성된 PK 순서 이외에 다른 엔터티로부터 상속받아 발생되는 PK 순서까지 항상 주의하여 표시되도록 해야 한다.
- FK 순서의 중요성 : FK도 데이터를 조회할 때 조인의 경로를 제공하는 역할을 수행하므로 이에 대해 반드시 인덱스를 생성하도록 한다. 조회의 조건도 고려.
6. 분산 데이터베이스와 성능
[1] 분산 데이터베이스 개요
- 데이터베이스를 연결하는 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역, 노드로 위치시켜 사용성/성능 등을 극대화.
- 분산되어 있는 데이터베이스를 하나의 가상 시스템으로 사용.
- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임.
- 물리적 Site 분산, 논리적으로 사용자 통합, 공유.
[2] 분산 데이터베이스의 투명성
1) 분할 투명성(단편화) : 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단편의 사본이 여러 Site에 저장.
2) 위치 투명성 : 사용하려는 데이터의 저장 장소 명시 불필요. 위치 정보가 System Catalog에 유지되어야 함.
3) 지역사상 투명성 : 지역 DBMS와 물리적 DB사이의 Mapping 보장. 각 지역 시스템 이름과 무관한 이름 사용 가능.
4) 중복 투명성 : DB 객체가 여러 Site에 중복되어 있는지 알 필요가 없는 성질.
5) 장애 투명성 : 구성요소(DBMS, Computer)의 장애에 무관한 Transaction의 원자성 유지.
6) 병행 투명성 : 다수 Transaction 동시 수행 시 결과의 일관성 유지, Time Stamp, 분산 2단계 Locking을 이용구현.
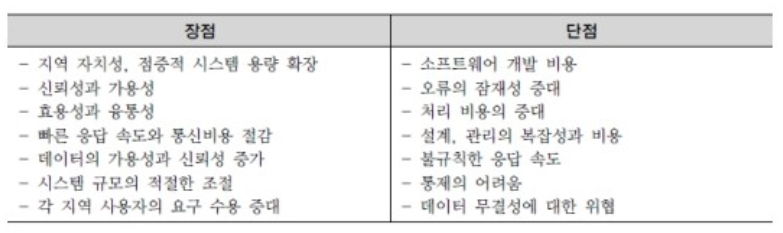
[3] 분산 데이터베이스의 장단점
- 업무의 특징에 따라 데이터베이스 분산구조를 선택적으로 설계.
[4] 분산 데이터베이스의 적용기법
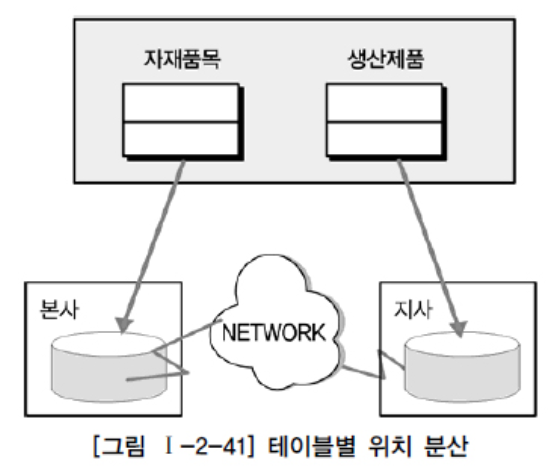
1) 테이블 위치 분산
- 테이블 구조 변하지 않음
- 테이블이 다른 데이터베이스에 중복 생성되지 않음
- 정보를 이용하는 형태가 각 위치별로 차이가 있을 경우 이용
- 테이블 위치를 파악할 수 있는 도식화된 위치별 데이터베이스 문서가 필요
2) 테이블 분할 분산
- 위치만 다른 곳에 두는 것이 아니라 각각의 테이블을 쪼개어 분산
1. 수평분할
- 특정 칼럼의 값을 기준으로 row단위로 분리
- 칼럼은 분리되지 않음
- PK에 의한 중복이 발생하지 않음
- 지사별로 사용하는 row가 다를 때 사용
- 타 지사에 있는 데이터를 수정하지 않고 자신의 데이터를 수정
- 각 지사의 테이블 통합처리
- 데이터 무결성 보장

2. 수직분할
- 칼럼을 기준으로 칼럼단위로 분리
- row 단위로 분리되지 않음
- 각 테이블에는 동일한 PK구조와 값을 가지고 있어야 함, PK는 하나로 표현하면 되므로 데이터 중복은 발생되지 않음
- 실제 프로젝트에서는 잘 안 쓰임

3. 테이블 복제분산
- 동일한 테이블을 다른 지역이나 서버에서 동시에 생성
- 프로젝트에 자주 쓰임
ㄱ) 부분복제

- 마스터 데이터베이스에서 테이블의 일부 내용만 다른 지역이나 서버에 위치
- 통합된 테이블을 한 군데(본사)에 가지고 있으면서 각 지사별로는 지사에 해당된 로우(row)를 가지고 있는 형태
- 본사 데이터는 통계, 이동 등을 관리, 지사 데이터를 이용하여 지사별로 빠른 업무 수행
- 지사에 데이터가 먼저 발생, 본사 데이터는 지사 데이터를 이용하여 통합하여 발생(광역 복제와 차이점)
- 다른 지역 간의 데이터 복제는 실시간 처리보다 배치 작업에 의해 수행(시간 소요, 데이터베이스와 서버에 부하 발생)
- 데이터의 정합성을 일치시키는 것이 어렵기 때문에 가능하면 한쪽(지사)에서 데이터의 수정이 발생하여 본사로 복제하도록 한다.
ㄴ) 광역복제

- 통합된 테이블을 한 군데(본사)에 가지고 있으면서 각 지사에도 본사와 동일한 데이터를 가지고 있는 형태
- 본사나 지사나 데이터 처리에 특별한 제약을 받지는 않음
- 본사에서 데이터가 입력, 수정, 삭제가 되어 지사에서 이용하는 형태(부분복제와 차이점)
- 다른 지역 간의 데이터 복제는 실시간 처리보다 배치 작업에 의해 수행(시간 소요, 데이터베이스와 서버에 부하 발생)
4. 테이블 요약분산
- 지역, 서버 간 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우
ㄱ) 분석요약

- 각 지사별로 존재하는 요약 정보를 본사에 통합하여 다시 전체에 대해서 요약정보 산출
- 동일한 테이블 구조를 가지고 있으면서 분산되어 있는 동일한 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식
- 각종 통계 데이터 산정 : 모든 지사의 데이터를 이용하여 처리하면 성능이 지연되고 각 지사 서버에 부하를 주기 때문에 업무에 장애 발생 가능성 있음
- 지사에 있는 데이터를 이용하여 본사에서 통합하여 요약 데이터 산정
- 통합 통계 데이터에 대한 정보 제공에 용이
- 본사에 분석 요약된 테이블을 생성하고 데이터는 일반 업무가 종료되는 야간에 수행하여 생성
ㄴ) 통합요약

- 각 지사별로 존재하는 다른 내용의 정보를 본사에 통합하여 다시 전체에 대해서 요약정보 산출
- 지사에서 요약한 정보를 본사에서 취합하여 각 지사별로 데이터를 비교하기 위해 이용
- 통계데이터에 대한 정보제공에 용이
- 본사에 통합된 요약된 테이블을 생성하고 데이터는 일반 업무가 종료되는 야간에 수행하여 생성
5. 데이터베이스 분산 설계의 효과적 적용
- 성능이 중요한 사이트에 적용
- 공통코드, 기준정보, 마스터 데이터 등에 대해 분산환경을 구성하면 성능이 좋아진다.
실시간 동기화가 요구되지 않을 때 좋다. 거의 실시간의 업무적인 특징을 가지고 있을 때도 분산 환경을 구성할 수 있다.
- 특정 서버에 부하가 집중이 될 때 부하를 분사할 때도 좋다.
- 백업 사이트(Disaster Recovery Site)를 구성할 때 간단하게 분산기능을 적용하여 구성할 수 있다.
'자격증 > SQLD' 카테고리의 다른 글
| [SQLD] 2과목 3장 SQL 최적화 기본 원리 정리 (0) | 2023.03.14 |
|---|---|
| [SQLD] 2과목 2장 SQL 활용 정리 (0) | 2023.03.14 |
| [SQLD] 2과목 1장 SQL 기본 정리 (0) | 2023.03.13 |
| [SQLD] 1과목 1장 데이터 모델링의 이해 정리 (0) | 2023.03.12 |